Highlights from ESEC/FSE 2018 – Day 1
Image above: An impertinent cat from the keynote presentation by Erik Meijer.
I’m at ESEC-FSE 2018, one of the leading scientific international Software Engineering (SE) conferences. The main event began today, after yesterday’s workshop. Here are my highlights for this first day:
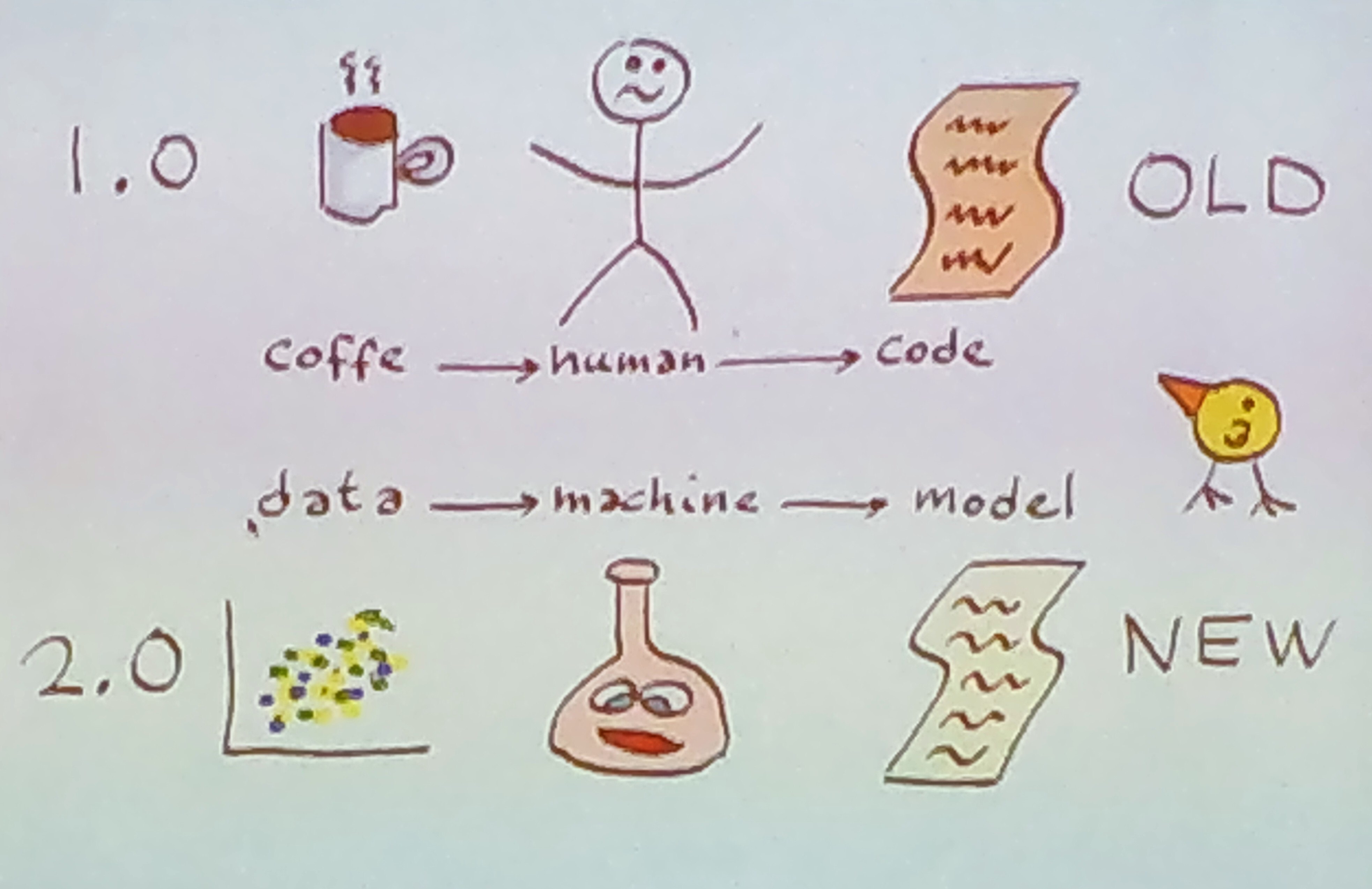
- The keynote, Erik Meijer, made a provocation: manual programming has failed, humans can’t do it properly (see the cat image above), so we should all be learning programs from data instead of writing them! This could (possibly) be accomplished with so-called Differentiable Programming.
- In large distributed systems, logs are often the only way to analyze erroneous program behavior, but they are huge (10+ TB at Microsoft) and unbalanced (most of the time, things work), so manual inspection is not feasible. By clustering logs using a vectorization technique, and correlating them with relevant KPIs, it is possible to automatically detect relevant problems. This has been used in actual Microsoft services. (See “Identifying Impactful Service System Problems via Log Analysis” and https://github.com/logpai)
- Modeling application logs as finite-state machines allows for faster and more sensible comparisons of different program behaviors. This can be used to study subtle behavioral differences, such as anomalous or malicious executions. (See “Using Finite-State Models for Log Differencing”)
- Deep Learning can be used to accomplish various SE tasks, such as (approximate) type inference and detection of functional similarity. Results are quite impressive in relation to the state-of-the-art. (See “ Deep Learning Type Inference” and “DeepSim: Deep Learning Code Functional Similarity”)
- More open-ended use of Deep Learning can also be achieved by embedding programs using specially crafted symbolic traces as training data. Applications include detection and automated correction of defects. The primitives used to build the symbolic traces are critical to the performance and may vary according to the kind of problem being addressed. (See “Code Vectors: Understanding Programs Through Embbeded Abstracted Symbolic Traces”)
- Anti-patterns in ORM can be automatically fixed by static analysis. We saw a tool for Ruby on Rails, which comes with a RubyMine plugin, to do just that. I wish I had this when I was programming in Ruby some years ago. (See “PowerStation: Automatically Detecting and Fixing Inefficiencies
of Database-Backed Web Applications in IDE” and a tutorial on YouTube) - Entropy of program changes can be used to measure commit risk. Yet another case in which entropy does something useful! (See “WarningsGuru: Integrating Statistical Bug Models with Static
Analysis to Provide Timely and Specific Bug Warnings”)
There’s a lot of Machine Learning going into Software Engineering, right? Certainly more than what I saw at ICSE in 2016. I like it. The proceedings are in the (payed) ACM DL, but you can probably find pre-prints of some of these papers in the authors’ sites.
Bonus: more memorable wisdom from Erik’s slides.